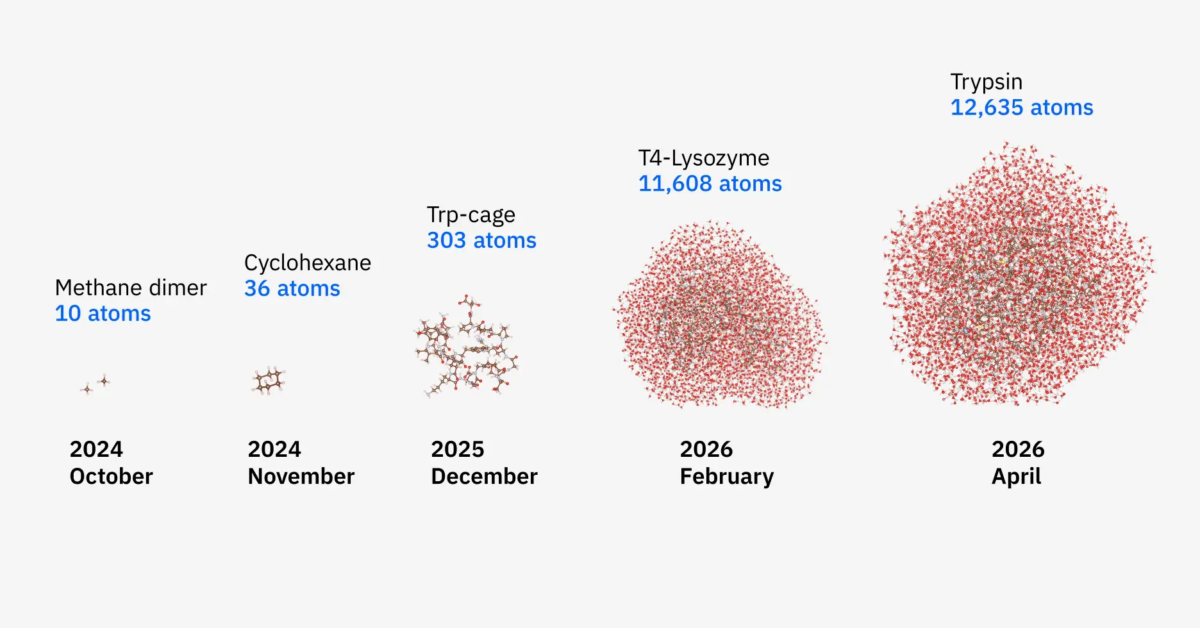
IBM is back with yet another exciting quantum computing announcement. Working with Cleveland Clinic and RIKEN, the company says it has simulated a protein with 12,635 atoms using a combination of quantum hardware and traditional supercomputers. That is well beyond the tiny, almost academic examples we usually hear about, and it starts to feel a lot closer to something scientists might actually use.
The protein is trypsin, a real enzyme, not some made up test case. That detail matters because the whole goal here is to better understand how drugs interact with proteins. If researchers can model that accurately in software, it could shorten development timelines that currently drag on for years and cost a fortune. That is the promise, at least.
IBM calls the approach “quantum centric supercomputing.” In plain English, it is a hybrid setup. Classical computers break the molecule into smaller, manageable pieces. Quantum processors then handle the parts that involve complex quantum behavior. Once that is done, the results get pulled back together into a full picture. It is less about replacing existing systems and more about letting each one do what it does best.
What stands out is how quickly things have scaled. Not long ago, this method was being used on systems with maybe 10 atoms. Now it is handling more than 12,000. That is a huge jump. IBM also says accuracy improved by up to 210 times in parts of the workflow. Sounds impressive, but it also raises the usual question about how much of that holds up outside a tightly controlled research setup.

On the hardware side, the work used IBM’s Heron quantum processors, with up to 94 qubits active during parts of the simulation. Those were paired with serious classical systems, including Japan’s Fugaku supercomputer. That kind of hybrid approach is doing most of the heavy lifting, because quantum machines still cannot handle these problems on their own.
There is also a software piece here that probably deserves more attention than it will get. The team developed a new hybrid algorithm designed to reduce overhead and better map chemical systems onto quantum hardware. That kind of work is not flashy, but it is necessary. Throwing more qubits at a problem without improving the math behind it is not going to get very far.
So where does this leave us? IBM is framing this as progress toward real world use cases like drug discovery and enzyme modeling. That might be fair, but it is not like pharmaceutical companies are about to swap out their existing workflows tomorrow. This still feels early.
At the same time, it does not feel like empty hype either. This is the kind of incremental progress that could eventually add up. Quantum computing is not taking over anything yet, but it is starting to look a little less like a science project and a little more like a tool that might earn its keep.
Support independent tech journalism
NERDS.xyz is independently owned and operated. If you enjoy my coverage of Linux, AI, hardware, cybersecurity, and tech culture, consider supporting the site on Ko-fi.
Support NERDS.xyz